
Using Linux
Old School Command Line Interface
Derivation of Various Shells (Command Line Interpreters)
Before Linux there was Unix. Unix was a multi-tasking multi-user operating system created at Bell Labs, originally to share the resources of a PDP-7. In those days, computers didn’t have the horsepower or graphics hardware to support a graphical interface so things were done using a command line interface.
The shell or command line interpreter is still widely used today because of it’s ability to connect various tools together and perform scripted operations. Most graphical programs are more monolithic and quite different in their approach to solving problems. It is best to be familiar with and fluent in both environments as both have advantages and disadvantages.
AT&T licensed Unix to Berkeley, University of Southern California, and from there a variant known as BSD emerged. The AT&T product by this point was known as System-V, and almost every other version of Unix derived from one of these two.
The original AT&T Unix used an interpreter which ran on Version 7 (which oddly enough predated System V) was developed by Stephen Bourne at Bell Labs and is referred to as the Bourne Shell, /bin/sh.
Bill Joy (of Sun Microsystems fame) and others at Berkeley developed an alternative shell called C-shell or csh, /bin/csh or Tenex, Total, or Terrible C-Shell (depending upon whom you ask), /bin/tcsh a superset of csh. This shell added features like job control, command line history, and aliases. However, it featured an entirely different syntax and as a result could not run scripts written for the Bourne shell. Today most Linux systems use a derivative of Bourne shell canned Born Again Shell, or Bash. Some Debian derived systems use Dash shell, Debian Almquist shell, /bin/dash, which is a super-set of Bash which itself is a superset of sh,
Linux code is not derived from Unix but the functionality of Linux is essentially identical. Modern commercial Unixes owe a lot of their newer enhancements to Linux. Most notably a Linux streamlined system call interface significantly improved performance over the older Unix method and now has been incorporated into Unix as well. While this article focuses on Linux, most of what is written here will perform identically on Unix systems.
The instructions I am providing here assume a Bourne shell derivative though most will also work with csh and tcsh as what I am describing are simple commands that don’t invoke the greater complexities of these shells.
Bourne shell derivatives include the Almquist shell or ash, which primarily was written to provide Bourne shell functionality without an AT&T license, the Bourne Again Shell, or bash, the Debian Almquist shell or dash, the Korn shell or ksh which was written by David Korn while at Bell Labs, the pdksh which is a semi-functional public domain version of ksh, MirBSD shell mksh which is descended from the original ksh and pdksh, and Zsh which is backwards compatible with bash, which in turn is backwards compatible with sh. We have most if not all of these shells available for your use and what is shown in the following examples should work with any of these.
Because these shells are supersets of the original Bourne shell, often a link from /bin/sh to one of these shells, most frequently bash and dash, is provided on Linux systems, If you pull up a man page for sh, you will frequently get a man page for bash or dash depending on whether the system is Redhat or Debian based. Likewise, because tcsh is a superset of csh, often you will find csh is a link to tcsh on Linux systems and the man page for csh will refer to tcsh.
Derivatives of the C-shell, csh, include tcsh (which I’ve heard referred to as the Tenex C Shell, Total C Shell, and Terrible C Shell, I’ll leave it to you to determine which fits best), and something called the Hamilton C Shell, to which I’ve never been exposed. If you are familiar enough with the csh or tcsh to be using them then you probably don’t need this article so I won’t be covering them here.
Terminal Window Command Prompt
Windows 10 and 11 have ssh built in. These features are not enabled by default so you have to enable them before first use. Once enabled, ssh will work either in command prompt or power shell. I recommend power shell because it will honor either windows commands like dir, or Linux commands like ls, allowing you to use whichever you prefer. Older windows systems require putty. Putty provides a terminal window and an ssh connection to a remote host such as one of our shell servers.
When you connect from either a Mac OS X based machine or Linux, you will typically open a terminal window and then use ssh to connect to a remote host by typing “ssh login@hostname“, for example I would connect to ubuntu by typing “ssh nanook@ubuntu.eskimo.com“. You can find a complete list of shell servers at https://www.eskimo.com/services/shells/servers/. I would then get a password prompt and enter my password unless I had setup public key authentication.
Here is an example of a terminal window which is connected to shellx via ssh and configured for the default command prompt.
 The default primary command prompt for Bourne shell derived shells is “$ “. The default secondary prompt is “> “. However, most of our servers have a default login script that changes the primary command prompt to: “user@server:current working directory$.
The default primary command prompt for Bourne shell derived shells is “$ “. The default secondary prompt is “> “. However, most of our servers have a default login script that changes the primary command prompt to: “user@server:current working directory$.
The primary prompt is the prompt you receive when the shell is ready to receive a command. The secondary prompt is a prompt you receive when more input is needed to complete the command.
Shell Variables, Environmental Variables
The shell isn’t only an interactive command line interpreter. It can also take input from a file or pipe. The shell is a complete programming language with variables, mathematical operators, comparison operators, conditional branching, loop constructs, meta-evaluation, and more.
The command prompts I just mentioned, these are not fixed. Those are only the defaults and they are actually two variables, PS1 is the primary command prompt and PS2 is the secondary command prompt. When you read these variables they are prefixed with a $, but when you set them or export them the $ prefix is not included. Also, until exported, these variables are available only inside the shell in which they are set, but once exported they become part of the environment available to any program that you run from the shell.
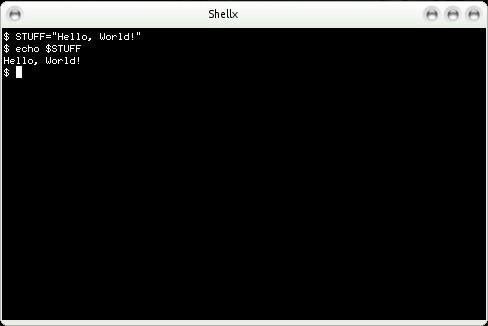
For example:
STUFF="Hello, World!"
echo $STUFFWould result in:
Hello, World!
 One hand feature of a shell is the ability to set a variable to the output of a program. Often times people use multiple hosts and work in different directories. To help them keep track of where they are they will set their primary prompt to include the hostname and current working directory. To include the output of a program in an environmental variable, include the program name in backticks like so:
One hand feature of a shell is the ability to set a variable to the output of a program. Often times people use multiple hosts and work in different directories. To help them keep track of where they are they will set their primary prompt to include the hostname and current working directory. To include the output of a program in an environmental variable, include the program name in backticks like so:
VARIABLE="`program`"
For example:
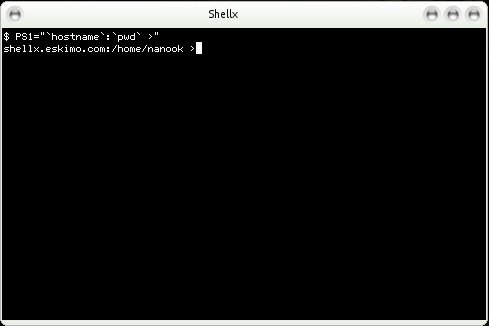 In this example, I set the environmental variable PS1, which is my primary prompt, to equal the output of hostname followed by a colon, then the output of pwd which prints the current working directory, followed by a space and then a greater than “>” symbol. You can see that my prompt became “shellx.eskimo.com:/home/nanook >” as a result, but if I was on a different hostname or changed to a different directory, that would be reflected in the prompt such that I would always know where I was. BTW: shellx is no longer a valid server name here, see https://www.eskimo.com/services/shells/servers/ for a current list of valid servers.
In this example, I set the environmental variable PS1, which is my primary prompt, to equal the output of hostname followed by a colon, then the output of pwd which prints the current working directory, followed by a space and then a greater than “>” symbol. You can see that my prompt became “shellx.eskimo.com:/home/nanook >” as a result, but if I was on a different hostname or changed to a different directory, that would be reflected in the prompt such that I would always know where I was. BTW: shellx is no longer a valid server name here, see https://www.eskimo.com/services/shells/servers/ for a current list of valid servers.
There are start-up scripts that a shell always runs at start-up if it is a login shell, and there are scripts that it runs every time whether it is a login shell or not. The default startup script for sh is “.profile” and for bash, “.bash_profile”. The per instance script that is read for every interactive bash shell is “.bashrc”. When bash is invoked as “sh”, it will read “.profile” rather than “.bash_profile”. These scripts are typically used to do things like setting your environmental variables such as PS1 and PS1 and exporting them.
There is a system wide start-up script read by all Bourne shell derived shells called /etc/profile that sets system wide defaults. Because it is read before your personal “.profile”, you can override these settings.
Variables that you do not export are not available to programs you invoke except if they are exported by the system wide start up scripts or your start up script.
Input / Output Redirection and Pipes
There are three descriptors associated with an interactive shell and any programs you start from that shell. File descriptor 0, also referred to as stdin, is normally attached to your keyboard. That is whatever you type, is fed to the program which it can read from file descriptor 0, or stdin.
File descriptor 1 is stdout. This is normally fed back to your display as normal non-error output. File descriptor 2 is stderr. It also is normally fed back to your display but contains only error output. Having error output go to a different descriptor allows you to process errors differently than normal output.
It is possible to redirect the input of a program, including the shell itself to take input from a file or another device rather than your keyboard. In Linux, every device except for the ethernet controller, is represented by a device. In other Unix systems the ethernet is also represented by a device.
One common device is called a data sink and it is /dev/null. Any data redirected to this device goes into a black hole never to be seen again.
Let’s say you are going to compile a large program and the make process generates a huge amount of useless noise. You are only interested in any errors that may occur. You could do this:
make program > make.out 2> make.err &
The ‘&’ tells the shell to run the command in the background so you can go do other things while it’s running. The ‘>’ symbol without a number redirects stdout, in this case to a file named “make.out”. The ‘>’ symbol proceeded by a number redirects that file descriptor. So in this case you are redirecting stderr (error output) to a file named make.err.
It is possible to append to an existing file rather than creating a new file or overwriting an existing one by using the ‘>>’ redirection symbol in place of ‘>’.
When the process completes you can examine these files to check if the process completed normally and if not what errors occurred.
One very useful feature of Unix and Linux are pipes. Pipes allow you take the output of one program and chain it into another. For example, if you wanted to know how many files are in your directory you could type:
ls -a | wc -l
The program “ls” lists directory entries one per line. The ‘-a’ says to also list files that begin with a ‘.’, otherwise they are hidden from view. The program “wc” is word count, counts words by default, but with the ‘-l’ it counts lines instead. So by piping ls -a into wc -l, you get a count of all of the files in your directory. This is a trivial example of what you can do with a pipe.
Three Very Important Commands
- apropos
- Apropos is used like this, “apropos topic”. It will find man pages that contain the topic specified. It is useful when you want to do something but can’t remember or don’t know the name of the command to do it.
- man
- This command displays manual pages. It is used like this, “man man”, in this example it provides a manual page on the man command. The manual pages are divided into sections with ordinary user commands in section 1, system calls in section 2, C library functions in section 3, devices and special files in section 4, file formats and special conventions in section 5, games in section 6, miscellaneous stuff that doesn’t fit elsewhere in section 7, and system administration commands in section 8. Normally it is not necessary to specify a section unless the same topic exists in more than one and it becomes necessary to disambiguate them.
- info
- A lot of software developers don’t like to document enough to bother to learn troff in which man pages are written. As a result a lot of modern Linux documentation exists as info pages which are difficult to navigate and horridly formatted. None the less, sometimes that is the only place you can get information on modern Linux software.
The Linux File System
Actually there are many different Linux file systems but on the user level they all share common attributes. They all are hierarchical, basically a tree structure that always starts with the root directory, “/”, then various directories under the root such as “/home”, where home directories generally reside, “/dev”, where devices reside, “/tmp”, for temporary files, etc. For example, if your username is quebert, then your home directory would be “/home/quebert”.
The differences in file systems are largely internal. The most commonly used Linux file system at this time is ext4. It is also used by new Mac OS X systems and some other Unixes. However there are many competing file systems also supported by Linux such as “xfs”. These other file systems have different advantages. Some are faster under certain circumstances, some make more efficient use of disk space. Some support larger file systems than ext4 can. Most of these advantages are moot to the average home user.
A command which will show a text representation of a file system layout, or a portion of that file system starting at the current working directory, is “tree”. Here is an example of the output of tree on my Pictures directory:
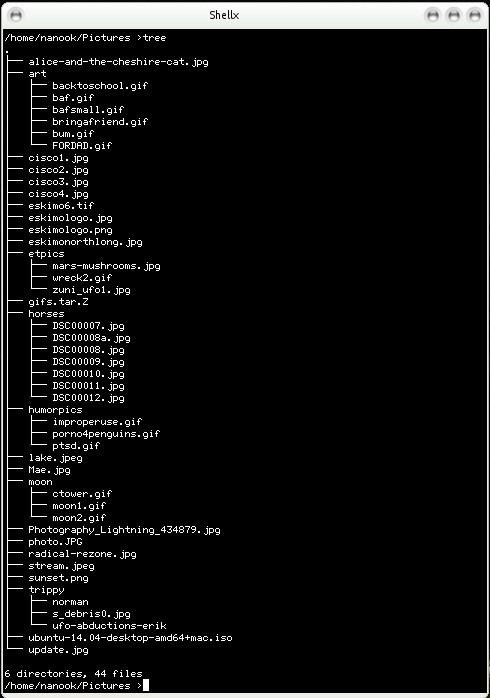 Since a typical Linux system will contain anywhere between several hundred thousand files and several tens of millions, this is not a practical way to view a large file system but is illustrative of the file system layout.
Since a typical Linux system will contain anywhere between several hundred thousand files and several tens of millions, this is not a practical way to view a large file system but is illustrative of the file system layout.
Navigation
The normal way to view a listing of files in a directory is with the command “ls”. Given by itself with no arguments, it will show the non-hidden file names in the current working directory without any attributes.
File names beginning with a “.” cause the file or directory to be hidden from view. These are normally used for things like personal configuration files for various applications.
To see these files, use “ls -a”, the “-a” says to show all files.
Often you will want to know more about a file besides it’s name. In this case, use “ls-l” to get a listing of files with their attributes, This will normally list the type of file, it’s permissions, the owner and group of the file, it’s size, modification date, and filename. Some versions of “ls” require an “–author” argument to show the owner, “ls -l –author”. It is also possible that some sites may define aliases to “ls” in /etc/profile that alter the normal behavior.
For a complete listing of all the arguments available to “ls” and the meaning of the output generated, see the “ls” man page. The specific arguments available to “ls” and the output varies with different Linux distributions.
So far these commands have shown you how to see a list of files in your current directory. To see a list of files in other directories use “ls /some/path”, where /some/path is the path that you are interested. If the path starts with “/” it is what is known as an absolute path and is the full path of a file or directory starting at the root directory.
If a path doesn’t start with a “/” then the path is a relative path. That is to say it is relative to the current working directory. Let’s say you are in your home directory and you type “ls Pictures” and your login is “smug”, then the path would be /home/smug/Pictures.
There are two special directory entires in every directory. They are “.” which is the current working directory and “..” which is the parent directory, the directory the current working directory resides in. In the root directory, the “..” is also the current working directory since there is no where else to back up to.
To change to a different directory, use the “cd” command. The cd command has several potential arguments.
- cd
- Typing “cd” with no arguments returns you to your home directory.
- cd /absolute/path
- Takes to you the absolute path relative to root. This must be a directory, you can not change directories to a non-directory.
- cd relative/path
- This takes you to a path relative to where you are. Again, you can not change directories to a non-directory.
- cd ~
- This also takes you to your home directory but in addition can be used to form paths relative to your home directory.
- cd ~/path
- This is an example of a path relative to your home directory.
- cd –
- This takes you to the last directory you were in.
- cd ..
- This takes you to the parent directory of the directory you are presently in.
- cd .
- This is essentially a non-operation since “.” is your current working directory.
Ending a Terminal Session
If the shell is a login shell (you connected via ssh and logged in), you can usually exit with “logout” or control-D (hold the control button down and press D).
If the shell is not a login shell, for example if you logged in via a graphical remote desktop and then fired up a terminal, “exit”, will end the terminal session.
Disk Usage
The command to find out how much disk space you are using out of your allowed disk quota is “quota -v”.
On some machines you can get a more readable form by adding “-s” but this is not supported on all systems.
The command “du -s ~” will show you the disk usage in terms of the total of the files in your directory however it will not accurately reflect your usage in terms of quota. The reason for this is that du bases it’s output on the file size, but the file size can be less than the disk space allocated. The reason for this is that the ext4 file system allocates a minimum disk unit of one block and on modern drives this is usually 4kb. So a file might only be 1 byte long but will use 4096 bytes of disk space. This is a minor drawback of the ext4 file system.
File Manipulation
On modern Linux systems, renaming a file is synonymous with moving it. This was not true of early systems which were incapable of moving a file across partitions. But today whether you are renaming a file or moving it to an entirely different part of the file system or even another partition, the command is the same:
mv oldpath newpath
If the destination path is a directory then the file will be moved with it’s original name into that destination directory. If the source path is a directory, then the entire directory and all of it’s contents are moved.
To remove a file use the rm command is used. The general form of the command is:
rm -args filename(s)
Some generally useful arguments are “-r” which says to recursively remove a directory and it’s contents, “-f”, which says to remove the contents even if they don’t have write permissions, and “-i” which is interactive and generally used with a wildcard file argument to remove only those you really want to remove. It asks for confirmation for each file that is to be removed.
To copy files, the simplest command to use is “cp”. The “cp” command can copy files or entire directories. It has many options, see the cp man page for details.
cp filename [newfilename] [-a newdirectory]
These are examples of copying an individual file or entire directory.
To concatenate two or more files into one file containing the contents of the first two you can use the cat command. If you get a SSL certificate, it typically will contain the local portion, any intermediary certificates, and the root certificate in separate files, but a lot of Linux software expects them to all be in one so you can use the cat command to combine them like this:
cat local.crt intermediate.crt root.crt > all.crt
Often times cat can also be used to output the file verbatim with no paging. Any characters, control codes, binaries, everything will be output exactly as it exists in the file with the cat command.
You can view a file with more or less. More is a simple paging program that pages the output of a file to your screen. Less is an advanced version of more that permits backwards paging and other capabilities lacking in the original version of more.
For example, you can view the contents of the system message of the day file with the following command:
more /etc/motd
The more command is available on even the earliest Linux systems and less is available on all modern Linux systems.
Commands
Linux is unique in it’s ability to allow commands to be written in virtually any language and executed in a way that is completely transparent to the user.
Commands can be built-in to the shell you are using, “echo” is an example of a command that is typically built-in. Commands can be external binary executable programs compiled from a wide variety of languages although C and C++ are most commonly used, and lastly commands can be written in any scripting language such as shell scripts, python, perl, php, ruby, and many others.
The first line of a scripted language command contains, “#” followed by the path to the interpreting language. For example, a shell script would start with “#/bin/sh”, a php script with “/usr/bin/php”, perl with “#/usr/bin/perl”, etc. In some cases there would be an argument after the path, particularly with perl to specify taintperl.
Terminal Parameters
In the old days, the way we’d normally connect to a computer is through a serial RS-232 port. In modern times we usually connect through ssh over a TCP/IP network of some kind. In order to provide the same functionality as provided over a serial port, Linux has PTYs, psuedo-ttys. These basically make it look to the application like you’re coming over a serial connection even though you are not.
The keystrokes used to do things like backspace, interrupt, or kill a program are not fixed in Linux, rather they can be set with the command stty. The most common key to change is the erase key, the key that backs up one position and erases the character. Some people prefer to use the erase key, some people prefer to use the backspace key, and some keyboards generate altogether weird characters when the backspace or delete key is used.
The stty command allows you to set this key and more. To set the erase key to backspace, the following command will work:
stty erase ^h
To set the erase key to delete use:
stty erase ^?
The ^h stands for control-H, and ^? for Delete. Backspace normally generates control-H. Other keystroke functions such as the key to interrupt or kill a program can be set. Another useful key to set is the eof key. On most machines ^D indicates an end of file, but on Mac systems it is ^Z. This is also true of old CP/M machines though you are unlikely to run into one of those these days.
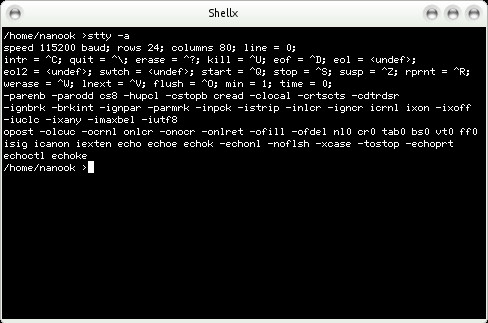
Please note that the baud rate is irrelevant over a TCP/IP connection and only applies to a true serial connection or a USB serial port converter connection. You can see all of the settings by typing:
stty -a
 Who Else is Online
Who Else is Online
There are several related commands for finding who else is online. The “who” command and “w” command show who is online locally. The “who” command shows what tty or pty they are on. It also shows where they connected from. The “w” command also shows this information but the hostname field is shortened to make room for other data and so is often truncated. The “w” command also shows how long they’ve been idle and what command they are executing.
You can see who is logged in to other machines on the local network by using the command “rwho”. It does not provide any information about what they are doing.