
I am taking debian.eskimo.com down for about an hour to move it from one host to another less occupied host. The only person currently logged in has been idle for 25 hours. If you need a Debian based host in the meantime, Mint and Ubuntu are presently available.
Category Archives: Uncategorized
Ubuntu Upgrade – Vivid -> Wily
An upgrade of ubuntu.eskimo.com from Vivid Vervet to Wily Werewolf is underway. When it completes, a reboot will be necessary to activate the new kernel.
Maintenance Tonight
Tonight I’ll be installing a shelf and an upgraded server in the co-location cabinet. Hopefully this will not disrupt any existing services. I’ve got the wiring strapped down now so the chances of accidentally unplugging something are significantly reduced.
I do have to move the connection to the co-lo providers router to a different jack which hopefully will eliminate problems with an existing flaky jack and this will interrupt service briefly.
When the new server is operational, I will be moving some of the existing guest machines to it. This will cause some interruptions but these are mostly little used shell servers like opensuse so it should not be too disruptive.
Since I will be at the co-location facility and not here, I won’t be able to answer the phone live. If you do encounter a problem please either use the Support -> Tickets ticket system or leave a voice mail.
Friday Maintenance 8pm-11pm
On Friday evening I will be going to the co-location facility to install a cabinet shelf and upgraded server.
While I am there I will also be moving an the Ethernet connection that feeds our cabinet to a different jack which hopefully will eliminate a marginal connection with the existing jack.
The latter work will require a brief interruption in network connectivity.
Mail Server Constipation
Our incoming mail servers got very clogged up. There were a number of contributing factors. When I recently moved them I didn’t allocate enough RAM for them to operate efficiently. CentOS recently pushed out a broken update for fail2ban and so a lot of crap that is normally blocked was hitting them. A virus was released in the wild and circulated fairly well before the clam-av folks got a signature for it in their database. There was no bounce time limit configured.
All of these things have been addressed and now they’re cleared out and functioning normally.
Fail2Ban – CentOS 6.7
This is a posting for those who administer Centos 6 based systems with the hope that it will save you some grief.
There is a bug in the current version of fail2ban being distributed in the CentOS 6.7 repositories. It will not create IP table entries.
The cause is the inclusion of the -w (locking) flag in the current version of fail2ban which is not supported in the version of iptables used.
The fix is to edit /etc/fail2ban/action.d/iptables-common.conf and remove the -w flag.
Shellx
My apologies to everyone on shellx this evening. I accidentally powered it off, meaning to halt a different machine that I was experimenting with NetBSD on and accidentally hit the wrong machine.
Debian
When I re-installed Debian, I neglected to create a ‘postfix’ user locally and so postfix wasn’t starting up. This meant that any application that tried to send mail using the local mail agent (as opposed to using mail.eskimo.com) would not have succeeded.
This has been corrected.
I am still re-installing software on Debian. If anything you need is missing please let me know and I’ll bump it to the top of the priority stack.
Messy Upgrade But Worth It!
I apologize that the last two months have had some difficulties and interruptions but there was good reason for it.
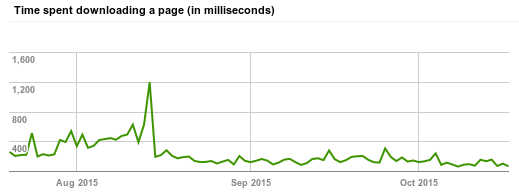
As you can see, web response latency spikes are GONE. This means people viewing your web page hosted here will never see a delay.
You can verify this for yourself by signing up for Google Webmaster tools, on your site hosted here, and following the Crawl Stats (under the Crawl pull-down).
In addition to the improvement of web response time, all user data is now on RAID10 disk arrays. RAID10 means both mirrored (for redundancy) and stripped (for speed).
Drive failures will not result in lost customer data and the read speed is doubled. RAID10 keeps a fully redundant copy of your data, not just hash sums, so there is no rebuild time in the event of a failed disk.
Mail Is Up
Mail is back up. It took less time than I anticipated.